American Shipper: Big data’s benefits to freight rail and the overall supply chain
FreightWaves: What do AI and big data look like in the freight rail industry?
Forbes: Let’s start with big data because big data [large volumes of data] is a phrase. … What’s interesting to me in freight rail is that data collection has been going on for years in terms of the instrumentation. The wayside and signals and all of those types of things have been around for a long time. And we’ve seen the [use of] sensors increase exponentially over the past five or so years, particularly on the rolling stock itself, locomotives, wagons, as well as by the wayside.
So rail has a lot of data to analyze, but that data has been analyzed in a kind of real time or static sense. A sensor goes off and tells me now about something that I need to react to now.
What’s been happening over the last five years is that we’ve started to say, “Let’s collect that data over the last five years and see what happens over time rather than in the moment.” And so, the first wave of big data/AI, machine learning has been the use of predictive technologies. If you can tell me about how something performs historically — and particularly how it fails — then you can start to predict failure based on a whole range of attributes and variables.
That was the first wave of big data, which was to say, “Huh, this is cool! We can use this data collected over time for predictive analytics.” And that continues to happen more and more.
As we have more connected sensors, we’re collecting this data and people can do predictive analytics and see big wins around those things like safety, reliability and efficiency, condition-based maintenance. Keep in mind that rail is a capital-intensive business, so anything you can do to improve the efficiency or reliability of those assets is going to have a big impact on your railroad.
Looking into the future, I think what’s exciting — the surface has barely been scratched on this, quite frankly — is you can improve the operational efficiency of what you’re doing: deciding how to operate, what to operate, when to operate, the planning and scheduling function of a railroad. … [Through using] all that data and understanding how things perform, we can build an operational plan that is more robust and more in tune with the historic performance of what we know about things like seasonality.
It’s not building operational plans in this laboratory condition where you say, “All things being OK, we’ll build a plan and we’ll operate and we’ll be fine.” We know that will never happen. We know that things will never be fine. The problem is we’ve never had a good way of knowing.
But now we can imagine and predict and use this data to have a better idea of how it will be fine and how things will vary. We can build our plans with flexibility and robustness to deal with a known level of variability rather than an unknown level of variability. … We can make better assumptions and use big data to inform the algorithms of artificial intelligence to come up with plans based on a level of variability that’s more predictable. And I think that’s really cool. It’s a step change in the way people think about planning and operating their railroads.
Forbes: It’s an interesting question. The short answer is yes, probably. The longer answer is there are a couple of things happening simultaneously, and they’re not mutually exclusive. There’s an interplay between … automation and connectivity.
Automation in rail is a bit different than automation in trucking. Automation in rail isn’t all about how do we handle an autonomous train. That’s a small portion of it. Think about a larger train and how much more freight it’s moving [than a truck]. Trucks are in order of magnitude smaller.
Automation for removing a trucker is a bigger net gain for the trucking industry than it is for the freight rail industry. … Automation in trucking is a threat to rail in terms of overall efficiency and competitiveness, but the response of the rail industry [shouldn’t be] to do automation to get the same result — i.e., remove the engineer or the driver. It’s for other efficiency reasons.
It’s interesting because I had a conversation with some folks at Rio Tinto in western Australia. They’ve got iron ore trains that have been the pinup for railway automation. What almost surprised them was that the real benefit was operational flexibility — not to have to worry about train drivers. Train drivers have restrictions of hours, of breaks, changing drivers that slow the train down — all the things you have to do that change the way you operate a train because the driver is present. Yeah, removing the driver is removing the cost, but the ability to run trains with more fluidity, to run them through the network in a more automated way — for North American Class Is, for example, velocity doesn’t get talked about as much as it used to, but that velocity is the key for any rail operator. … That’s the kind of automation holy grail for rail, to have this fluidity to your network.
Voice Technology: The bridge between today and tomorrow’s logistics systems
In most warehouses, pickers have only one way to interact with systems. Maybe it’s voice-directed work or RF scanners. Maybe it’s manual data entry. The future of picking, and worker productivity in general, is multi-modal interfaces with systems. To clarify, by multi-modal we are talking about workers using at least two technologies to communicate back and forth with the WMS and other systems.
Supply chain managers want to know which combination of technologies offers the best performance and the best ergonomics for the worker. A risk here is increasing complexity for the worker. Too many input devices, or the wrong combination, can be counterproductive. Imagine a picker tapping a tablet while holding an RF and a box. It’s cumbersome.
Voice is positioned as a keystone of the multi-modal worker. As a hands-free, eyes-free solution, workers can leverage voice seamlessly with other tools. The best part is that voice integrates with these other systems. So instead of two disparate tools, voice brings them together as one solution.
For example, vision and voice are a handy pair. As a heads-up display (HUD) workers wear on the warehouse floor, a vision system directs workers to products; provides diagrams and drawings of products, and other visual aids for jobs. Voice technology in this application allows the picker to confirm tasks with vocal commands. Then, the vision system displays the next instructions on the HUD. Voice will also supplement information to ensure workers arrive at the proper destination. With a voice-vision setup, the worker completes tasks without taking his eyes away from the work to click on screens or log data.
This setup also applies to augmented reality, where visual overlays guide workers through tasks while voice allows workers to update tasks and relay information to other systems. In the end, multi-modal work is about giving workers the right tools for the job. Voice opens opportunities to add multiple systems to a worker without encumbering him.
Voice & Big Data
Big data, business intelligence, and data analytics are three major resources influencing the future of warehouse management. Many companies have a warehouse management system capable of gathering granular data. Managers look to shop floor data to find out how many orders were shipped in a day, for instance. However, the WMS has a blind spot. It won’t account for how employees got to the products. This is a critical component contributing to pick time and overall efficiency.
Deeper insight leads to better decisions. Voice picking solutions help managers drill down on warehouse operations, including the details of every pick; how long it takes workers to complete a task, and where employees go throughout the day. Achieving more granular data on the movements of people and products fills a knowledge gap. Combining this information with the data generated by the WMS combine for a more holistic view of operations.
Voice & Robotics
Are robotics and automation taking jobs away from workers? Generally, no. The gap left by the shrinking labor pool in most markets created a need for technology such as autonomous mobile robots (AMRs) to step in. Instead of a contentious relationship, businesses look for ways to bring their workers and robotics together.
Voice-picking technology shows that there’s more than enough room in the warehouse for associates and supply chain robotics. Let’s compare a goods-to-person robotics application with and without voice as an example:
AMRs will bring a rack to the pick face, reducing travelling for workers. This makes picking faster and streamlined, while conserving worker energy—which brings greater quality of life for workers and potential employee retention benefits to boot. Typically in these applications there’s a large monitor attached to the robot showing the associate what to pick from the rack and where to put items. This process works fine. However, adding voice to the mixture allows workers to keep their eyes on the picking process rather than referring back to a screen. By being fed the pick instructions over the headset, associates squeeze more efficiency out of their tasks.
Co-bots is another example of a robotics-voice application. Here, a robot is assigned to a worker to perform tasks such as transporting picked items. The robot will often be away from the picker to transport items. Controlling the bot through the headset allows the worker to keep his eyes on tasks while using his robot as a rolling assistant throughout the warehouse.
Voice Technology Puts People First
We’ve covered how voice integrates with and benefits modern technologies. But, how does modern technology benefit voice? Voice systems are already known for reducing training time. By embedding AI into voice systems, the time to pair devices to workers is virtually eliminated. These “pick-up-and-go” solutions work without voice training exercises. This greatly reduces training time in general – improving the productivity and value of headcount.
From an employee satisfaction and retention standpoint, voice picking solutions help give employees a comfortable, safe, and ergonomic way to do their work. When you can lift a box safely with all of your fingers instead of trying to lift a box and balance a hand scanner all at once, you reduce risk of injuries.
A multi-lingual voice system provides worker benefits—it removes a language barrier and helps workers do their job however they feel most comfortable. Also, voice systems delivered through the Android operating system give workers valuable familiarity with their devices.
Thirty-Years Young
Our world is changing quickly. Customer expectations shift by the day. eCommerce has already disrupted how we think about supply chain. And the instability created by COVID-19 shrinks and swells demand, bringing with it uncertainty, complexity, and a lot of questions about the future.
Voice has been around for a long time, but that doesn’t mean it’s the same solution it was in the 1980s. We’ve seen it grow into a solution that increases productivity up to 30 percent and reduce mis-picks by as much as 50 percent. As voice applications grow into this new role as a bridge between multiple warehouse systems, the value of voice will continue to grow.
Amid the daily news churn, policy makers seem to be facing an impossible choice between saving lives and saving livelihoods. A close study of cautionary tales and hopeful examples from across the globe makes clear that social distancing, sheltering in place, and other mitigation efforts are critical to blunting the impact of the pandemic, despite the havoc they wreak on daily routines and markets. However, we know that the sooner we can return to safely congregating, the better.
How can we get there? We believe the answer lies in computation. We need to put as much data and computing power into the problem as we can, and now. Here’s a hopeful scenario we’ve discussed, one we believe could, with focused effort, be operational by summer.
The first step is getting the basics in order. South Korea is producing 100,000 test kits per day, and it has conducted more than 300,000 tests to date. That amounts to more than 40 times the per capita rate of testing in the United States. We need rapid and available testing capabilities. In fact, we needed them some weeks ago; now we must do everything we can to ramp them up as quickly as possible. We also need adequate supplies of personal protective equipment for health care workers and others on the front lines, along with ventilators and other lifesaving treatments. Putting those things in place, in combination with the mitigation measures currently being deployed, including lock downs of entire states, will buy us critical make-up time for deploying data and computers against the virus.
The next step is developing smart prevention capabilities rather than requiring blanket isolation and shutdowns. Our window is short — measured in months — for heading off what Bill Gates has characterized as potentially a once-in-a-century pandemic like the 1918 Spanish Flu, which killed at least 50 million people around the world. We have many technological advantages over those fighting that pandemic a century ago. In many ways, this is our most meaningful Big Data and analytics challenge so far. With will and innovation, we could rapidly forecast the spread of the virus not only at a population level but also, and necessarily, at a hyper-local, neighborhood level.
At MIT, efforts are underway to use existing mobile technologies to quickly develop game-changing, privacy-preserving contact tracing. When someone tests positive for COVID-19, health care providers could download the names of those who were in close proximity to the infected individual during the relevant time frame without accessing their comings and goings. With that anchoring information, computer scientists could then integrate data from a broad swath of sources — possibly including the amount of virus in wastewater — to forecast precise community-level infection risks.
That data would allow more-dynamic risk assessments, sufficiently precise and current to allow us to decide not whether schools and workplaces should be open but which ones should be open, and for how long. Air traffic controllers harness computing to coordinate the use of airspace in the face of uncertain weather patterns. A high viral-risk day for a specific locale could be the epidemic equivalent of a storm warning.
Such targeted isolation strategies would allow many more schools and businesses to stay open, which would be good. It would create challenges, too. Starting and stopping operations on the basis of current risk is not trivial; it can wreak havoc on supply chains and daily routines. Computing technology could make the process less disruptive and help ensure that we meet procurement needs and preserve workforce continuity. Logistics and transportation companies such as FedEx use human-artificial intelligence collaborations to plan their supply chains according to factors including predicted demand and transportation costs; similar collaborations could be deployed to improve the flexibility of our workplaces and schools.
Adapting such measures to fight the pandemic might teach us that physical presence is not always as necessary as we had thought. Remote work may simply become part of how we think about work. Here, too, computing could allow us to finely weigh the risks and benefits of having people work alongside one another. Much as sports franchises have used advanced analytics to compose their rosters, businesses and other organizations could develop metrics to team people up in risk-informed ways. New human-robot interface technologies, which allow users to communicate with robots that are stocking supplies, cleaning, or assembling equipment, effectively allow people to collaborate with machines as if working with human partners. The increasing availability of smart virtual-collaboration tools and intelligent collaborative robots in industrial spaces will be game-changers for remote work.
In 2019 the Baltic Exchange partnered with GeoSpock, a geospatial big data company, to look at building a digital platform for maritime industry emissions management. The partnership aims to work with the Exchange membership and broader industry to provide data access at a scale never before seen in the maritime sector.
To support this initiative, Baltic Exchange and GeoSpock published a white paper “The future of data in the maritime sector: driving change through geospatial data”. The document outlines the vision, and first steps in the initiative to help the entire maritime industry uncover value from the vast store of data sat just beyond their fingertips.
Part one, featured below, looks at where the industry is now. The 21st Century is often regarded as the dawn of the data age. The rise of the internet, smartphone and digital technology has completely revolutionised methods of communication and commerce, heralding seismic changes in the way society and organisations engage and transact with one another. Technology has enabled the instant access of large volumes of data and information from anywhere on the planet.
However, whilst digitalisation has revolutionised the transmission of information around the world, the ceaseless flow of physical goods also continues unabated. Older and more tangible than the electronic signals of the data age, physical trade remains no less vital to the globalised world of today. The internet and e-commerce may have brought companies into the homes of their customers, but it is still the job of the asset and logistics sectors to deliver. In this regard, the maritime industry reigns supreme, accounting for 90% of global trade volumes and delivering cargo more efficiently than any other method of global transportation.
Of course, the partnership between physical and digital methods of commerce and communication is also providing great benefits within the maritime sector. As international commerce increases, new markets are uncovered and trade routes developed to service them. Within the industry, organisations must now begin to leverage digital technologies to uncover the vast potential of their data.
The improvement in location data records provided by the widespread deployment of satellite constellations and improved ship broadband connectivity have already begun improving vessel operational performance as well as quality of life for thousands of seafarers. Round the clock connectivity facilitates oversight of even the most remotely operating vessels, allowing crews and companies to understand and react to changing local and global events as they occur.
As ships, ports and governments install more sensor systems, the volume of measurement data collected and collated for analysis is also rising exponentially. For the maritime sector, harnessing the potential of this data is now the industry’s greatest opportunity, but also its greatest challenge.
The dispersed, global nature of the sector, combined with strong competition between operators, does not easily facilitate the collaboration and cooperation required to fully harness value from data. In addition, a lack of effective methods of knowledge communication risk damaging the reputation of the industry in the face of greater scrutiny from customers and governments. The industry must therefore seize the moment itself and come together to unlock the full value of its pooled data, whilst demonstrating its credentials and importance on the global stage.
However, supply chains have existed since the industrial era. The main difference between their operation then, and how they are organized now, comes down to complexity. Often, supply chains were local or domestic. With technology making the economy more global, however, supply chains have gained more moving parts than ever before. In the late 90s and early 2000s, globalisation was a blessing for prices, but a curse for supply chains. With Big Data becoming a larger and more user-friendly asset, modern supply chains are being revolutionized.
Creating a wealth of shared knowledge
The biggest driving force behind this modern big data wave is that it can now be captured, understood, and utilized. While transactions were always captured data, creating a knowledge-sharing network based on the insights gained from big data analytics has become just as important, according to Forbes. Transactions were able to capture how, when, and where people make purchases.
With the addition of supply chain analysis, manufactures, retailers, and distributors can now optimize how best to get products to consumers. Thanks to geoanalytics, this can be done both faster and in a more cost efficient manner as supply chains reimagine their distribution routes. This has resulted in a 425% improvement in order-to-delivery times, and a 260% improvement in efficiency.
Managing risk and creating agility
In a recent study, it was found that 61% of leading supply chain management companies would consider risk very important. With better geoanalytics, tractability has also improved, which is leading to shipped products being accounted for from the start of their journey until the end.
Based on all the data collected from supply routes, successful deliveries, and problems that have been reported, those running supply chains are now armed with data that will allow them to recognize potential problems before they pop up, and proactively address potential kinks in their distribution system. This also speaks to the modern supply chain’s flexibility. With this additional knowledge in hand, routes can be changed to account for issues that arise after the delivery process has begun.
Customers: increasing retention and satisfaction
We’ve all heard the phrase “the customer is always right,” so if a customer changes their order overnight, or after a delivery has already gone out, they expect suppliers to meet their needs as soon as possible. While this can be a burden, 90% of customers who had a company fail to meet their demands will not do business with them again.
With this number in mind, suppliers will need to do everything they can to satisfy their consumers. Thanks to big data and analytics, suppliers will not only be able to get another order out the door efficiently, but they also have the opportunity to anticipate an increase in demand based on previous orders and market trends.
How Big Data and Analytics are adding efficiency to the ecosystem of the logistics sector
Forecast: The wide-ranging operations of logistics inherently depend on the demand and supply dynamics. Logistics players have to develop a strong understanding of different metrics including imminent demand, carrier performance, and so on. Doing so will help them in anticipating and planning fleets, inventory shortages and reducing costs, thereby paving the way for full operational capability. This is where Big Data plays a vital role in gathering projections for supply and demand dynamics.
Inventory Management: The use of Big Data and Analytics is aiding the logistics industry to implement several lean inventory management models that are resourceful and proactive. For instance, JIT (Just-in-Time) Delivery considerably decreases the dependency on both capital lock-in and the infrastructural requirement for managing inventory. However, such models are not easy to execute since even a small delay can stall the entire production or business process. Here, data creates end-to-end visibility in operations, thereby preventing unforeseen stock shortages and improving cost-efficiency.
Route optimization: It is beyond doubt that route optimization is an essential element of logistics and shipping. It enables an operator to create time-effectiveness and cost-efficiency in operations. This has a direct impact on a company’s bottom line as it can increase or decrease margins. Logistics players can optimize their routes and aptly chalk out a plan through an in-depth assessment of the shipment data, real-time GPS data, delivery sequence, weather forecasts, and holidays. The key deductions of this assessment can then be merged with other tech-driven approaches (such as Geo-tagging and Geo-fencing) for greater compliance and SLA breach prevention.
Insights: Comprehensive data points get generated for orders on both macroscopic and microscopic levels. This enables a company to gain several insights that have meaningful implications on for business operations. For instance, shipping analytics computes across-the-board data such as ticket-size of orders, PIN code performance, COD pay-out time, undelivered/RTO orders, and so on of various shipping players and geographies. This enables organizations to study trends and make informed decisions using them. Such insights can also be used for product placement, market strategy optimization, pricing strategies, operational risk management, and improving the product as well as service delivery.
Business Opportunities: The enormous amount of data doesn’t merely empower a business to function more resourcefully, but also helps tap the various business opportunities that prevail within the market. Business Intelligence solutions further help in finding bottlenecks in business operations and addressing them timely. For example, you can reduce RTO shipments by taking actions on undelivered orders through NDR (Non-Delivery Report) dashboard. Such processes also help businesses in becoming better organized as well as prudential.
With the ever-increasing influx of digital technologies in business processes, we are witnessing a paradigm change towards a future that has no room for pilferages and inefficiencies. Several avant-garde technologies including Big Data and Artificial Intelligence are empowering logistics solution providers with a data-driven approach and smarter business ecosystems. This is driving unparalleled competencies and effectiveness within the logistics sector, perhaps, even acquainting it with the future of operations.
Adoption Of Big Data And Data Analytics In Logistics
The onus for progress of a business in contemporary scenario, as we all know, is lying on the information adoption. Huge statistics exist in every sector while its analytics is frequenting the fascination and need of the world. Big data has been the key word for performance improvement and decision maker as defined in many Industries. Prevailing since a decade now, Big Data has ushered the world with its pervasiveness proving itself as a speedy and cost effective entity. Controlling the three V’s – Volume, Velocity and Variety, it has given impetus to the improvement of the Industry. There are enormous approaches where data has been adopted by its stakeholders but one domain that has boomed to infinitude with its application is the realm of Logistics.
Big Data Lake is a modern-day voluminous collection of facts that is floating across all the sectors. Big Data got its initial implementation in the carrier companies where this integrated data was efficiently tapped by extracting, transforming and loading information about the clients. In fact, the term has been promulgated by the e-commerce giants and forwarders like Amazon, which dwells on customer statistics. Every click of a customer online produces a data that is stored in these giant Lakes. The matter is then integrated to produce the desired result. It has not only expedited the process but has also assured customers with reliability on their consigners.
Advantages
As per the report by NASSCOM and Blueocean, India is reigning big data analytics with a value of $1.2 billion placing it among the top 10 big data analytics markets in the world. They have also anticipated the growth becoming eight-fold by 2025, soaring to $16 billion. With this vision in mind, every sector is now looking forward to Data analytics for its evolution.
Logistics being complex and dynamic natured Industry is outshining its competence with the adoption of Big Data. The technique with its advanced version is facilitating Logistics to improve its inefficiencies. Big data has helped to improve
Automate warehouses
Warehouses have now become mechanised with the use of robotic systems. The ease of finding a consignment in a warehouse has multiplied with the use of tracking sensors. Inventories have also been managed intelligently by taking advantage of RF tags, computer chips and other smart instruments.
Better route management
Optimisation of Logistics has been attained competently with better services from GPS data, weather data, and road maintenance data. It has assured less wastage of money by avoiding over usage of resources. Big data analytics also justifies the optimum use of vehicles and manpower on the same route by prior notification. It has thereby reduced late shipments by managing the route flow.
Better manpower deployment
Logistics, which requires more human resource functions better with the use of big data. The availability of adequate workforce at the foreseen time of haste has been helpful in handling odd situations especially with the client.
Last-mile deliveries
Big Data has revolutionized the Logistics by amplifying the last leg of the distribution network. As the consumer demands are raising so is the efficiency of this Industry. In order to provide with smooth facilitation of the end length of the consignment, Logistics are relying heavily on Big Data. With the help of smart phones, GPS, and IoT, many consignors are able to track the supply chain from start to finish enabling speedy more penetrable deliveries. They have reached out to more remote areas now.
Bringing more transparency to various supply chains.
Qualifying transport vehicles with modern GPS aided smartphones that reflect delivery network is so beneficial not only to the supplier but also to the customers who can trace the supply promptly with a click sitting at their homes.
Challenges
With Big Data, the trial comes with administering the mammoth data. The bigger the data, the more complicated it is to manage. It becomes difficult to ensure end to end functionality of this facility owing to unavailability of educated operators of the latest technology.
Secondly, presence of various stakeholders in the supply chain sometimes results in a gap. Logistics, at many times work with unstructured or semi structured data which brings a break in full extraction of the benefit of Big Data. Talking about the data itself, at times this data is unreliable and inaccurate.
So, multiple hands in one big supply chain are surely an uphill task to maintain. But there is always a scope of improving with a challenge.
Big Data undoubtedly will re-define the world of Logistics. It will not be wrong to say that in this very competitive world, the big difference in the achievers and the others will be the power to manage, analyse and apply big data. Cost-optimisation and customer experience both will depend on the smart application of big data by Logistics companies.
Disclaimer: The views expressed in the article above are those of the authors’ and do not necessarily represent or reflect the views of this publishing house. Unless otherwise noted, the author is writing in his/her personal capacity. They are not intended and should not be thought to represent official ideas, attitudes, or policies of any agency or institution.
What comes to mind when you hear the words Artificial Intelligence (AI)? Not too long ago, this phrase was reserved for talking about an imagined distant future where humans had robot servants and self-driving cars. Sound familiar? This is the world we live in today. We have personal assistants like Siri to answer any of our questions, Tesla’s that can get us from point A to B while we sleep, and endless filters on Snapchat that can transform our appearance instantly. The age of AI is here.
Machine Learning (ML) is a subset of AI that leverages algorithms to teach computers to make decisions like humans. One particular ML algorithm that aims to mimic the human brain is Artificial Neural Networks. These Neural Networks model the way our brain works by taking information, processing it through a sequence of artificial neurons, and producing an output (Figure 1). Neural networks power a large amount of today’s most prominent AI technologies.
Figure 1. A neural network modeled as a series of connected artificial neurons.
Introduction to Quantum Computing
Quantum computing is another innovation that has the potential to take AI to the next level. Quantum computers use the properties of quantum mechanics to process information. A traditional computer encodes information in bits, which can take a value of 0 or 1. In contrast, quantum computers encode information in qubits. Like a bit, a qubit can take on values of 0 or 1. However, a qubit is able to take on multiple states at the same time, a quantum concept called superposition. Therefore, two qubits can take on any of 4 possible states: 01, 11, 10, or 00. In general, n qubits can represent 2^n different states. This (very simplified) concept of superposition enables quantum computers to be much more powerful than traditional computers. They can represent much more information with much less computing power.
Quantum ML
A major roadblock for Neural Networks is the time it takes to train them to make decisions. It is not uncommon to spend weeks, even months, training a neural network due to lack of computing power. What if there was a way to harness the power of quantum computing to accelerate the training process, making these complex networks feasible? Enter Quantum Machine Learning.
Quantum ML is exactly as it sounds — the intersection of ML and quantum computing. Quantum ML aims to leverage the power of quantum computers to process information at speeds significantly faster than traditional computers. However, it is not as simple as transferring existing code from a CPU to a quantum processor. The code needs to be able to speak the quantum language of qubits first. Much of today’s work on quantum ML attempts to solve that exact problem.
Quantum Neural Networks (QNNs)
Approach
Functioning neural networks were a huge step forward for AI. However, existing neural networks are not yet able to harness the power of quantum computers. The first step towards creating a working QNN is modelling an individual quantum neuron.
Let’s examine the way quantum neurons are represented, and how QNNs compare to traditional neural networks. Since there are differing interpretations of quantum mechanics, there are different ways to represent a quantum neuron. One such interpretation is Huge Everett’s Many-worlds Interpretation. In short, this theory states that there are many parallel universes, each playing out every possible history and future at once.
It sounds highly complicated and abstract because it is. The Many-worlds Interpretation provides insight into how a QNN should behave. Just like how a traditional neural network mimics the human brain, a QNN can mimic quantum physics. Researchers at Penn State University use this interpretationto develop a methodology for building QNNs.
Traditional neural networks use a single network to store many patterns. What if QNNs used many networks to store many patterns, just like how there may be many universes that contain many realities? Quantum superposition could make this possible. Remember, superposition means that it is possible for a qubit to be in multiple states at once. Extending this analogy to neural networks, in theory, a QNN would be able to store all possible patterns in superposition at once. Each pattern in the network thus represents its own parallel universe.
This is one of many theorized frameworks for QNNs. If you are interested in the nuanced details of this theory, please check out the full paper. The actual implementation of a QNN that represents multiple parallel universes is not yet feasible. However, it is possible to model a single quantum neuron.
Figure 1: A classical model of an artificial neuron (a) and a scheme for the quantum implementation of the artificial neuron on a quantum processor (b)
In a classical neural network with a single neuron (a), the output is a weighted sum of the input vector passed through an activation function to map it to a binary output. At an abstract level, the QNN functions in the same way, but the implementation is different on a quantum processor. The first layer of the quantum network encodes the input vector into quantum states. The second layer then performs unitary transformations on the input, similar to how the weight vector functions in the classical neural network. You can think of unitary transformations as the computer translating from bits to qubits. Finally, the output is written on an Ancilla qubit, which produces the final output.
The implementation of the unitary transformations on a quantum processor is complex (Figure 2). At a high level, the input passes through a series of gates that are a part of a quantum circuit. These gates, denoted Z, H⊗N, and X⊗N, mimic the weight vectors in the traditional neural networks.
Figure 3. A quantum circuit for a an artificial neuron with 4 qubits.
This model is able to accurately mimic the behavior of a single neuron. However, it is not yet scaled to a deep neural network that consists of many layers of multiple neurons. A single layer model like this is able to identify simple patterns but is not yet scalable. This is a first step in efficiently training QNNs on quantum hardware, and a step towards realizing the Many-worlds Interpretation of neural networks.
Benefits of QNNs
QNNs seem extremely complicated and borderline incomprehensible. But there is a good reason why they are being explored. Per the Penn State research team, QNNs offer many advantages compared to traditional neural networks, including:
exponential memory capacity
higher performance for a lower number of hidden neurons
faster learning
processing speed (1010 bits/s)
small scale (1011 neurons/mm3 )
higher stability and reliability
These benefits solve most, if not all, of the limitations of traditional neural networks. This also means there is an extremely high incentive to be a first mover in the quantum ML space to exploit these advantages. Currently, there are many efforts being made to implement a fully functional QNN.
Current & Future Work
Research
The Quantum AI team at Google is one of the forerunners of quantum ML. The team constructed a theoretical model of a deep neural network that could be trained on a quantum computer. While they lacked the current hardware to actually implement the model, their results were encouraging. The framework they created will allow for quick adoption of quantum ML once the hardware becomes available.
Additionally, the Google AI team examined how neural network training will work on a quantum processor. A traditional approach to network training the weights randomly initializes the weights prior to training. However, they found that this approach does not work well when transferred to the quantum space. As a result, problems such as vanishing gradients will arise when training quantum models. With their research, the Google AI team is laying the groundwork for the future of quantum ML.
Quantum Problems
Focusing on getting traditional neural networks to train at quantum speed is a natural starting point and unquestionably highly important work. But the beauty of quantum computing will be the ability to solve quantum problems. These types of problems are far too complex for traditional computers to effectively model, let alone for human brains to understand. So what can quantum ML do that we can’t do currently?
Terms like unreliable, incomplete, duplicated, and obsolete are often used to describe government data assets, and it’s not uncommon for data-quality issues to be cited as a significant inhibitor to business analytics and systems modernization initiatives. In Australia, this challenge is magnified by the absence of a whole-of-government identifier, which hampers matching of citizen records across datasets. One might assume that Queensland OSR must’ve spent months cleansing its data in preparation for the machine learning prototype. However, its experience was that predictive algorithms can be applied to imperfect data with decent results. Elizabeth Goli, OSR’s Commissioner, explains: “despite the use of only three internal data sources and the current challenges we have with data quality, the machine learning solution was still able to predict with 71% accuracy the taxpayers that would end up defaulting on their tax payment. What this tells us is that you don’t need to wait for your data to be 100% perfect to apply machine learning.”
Although data cleansing will undoubtedly improve the accuracy of predictions, Ms. Goli observes: “the tool itself will actually become a key enabler in improving the quality of data.” This is due to the machine’s ability to interrogate massive data sets to establish probable linkages, and its ability to autonomously improve the accuracy of its predictions over time. So, while 71% is a good start, OSR expects to improve prediction accuracy to over 90% through the combination of increasing data quality and refinement of the predictive model.
During his tenure as CFO for the State of Indiana, Chris Atkins observed that “very few governments view data as a strategic asset. It’s usually not managed nearly so well as the government’s money. But it’s just as important for complex problem-solving.” Perhaps part of the reason is that government data – unlike public funding – is abundant (for example, just one use case, on infant mortality, required analysis of 9 billion rows of data). Such vast amounts of data can make it difficult to derive information and insights simply due to the impracticality of traditional disk I/O at such a scale. This is where in-memory data platforms come to the fore, enabling massive data sets to be interrogated within a timeframe that is acceptable for business purposes and workable for predictive analytics scenarios.
Another benefit of real-time computing is the ability to apply analytics directly to operational systems, enabling users to work with the most up-to-date version of data and to refine their data models dynamically. Mr. Atkins articulates the value of this capability to the business: “real-time data access lets you know with a high degree of certainty that your view of the issues is current and that the decisions you’re making with regard to policy and planning will be best calibrated to address the problems. Without real-time data, you’re managing the problems of yesterday – not today or tomorrow.”
For nearly half a century, the status quo has been that operational data is extracted, transformed, and loaded into data warehouses, to which analytical tools are applied and business reports are generated. ETL processes are typically run in batch overnight (often not every night), resulting in business decisions being made based on yesterday’s data (in a best-case scenario). The fundamental reasons for this are that transactional databases are not designed for reporting, and system performance can be impacted by analytical processes. Mr. Atkins describes how this issue manifested during initiation of the MPH project: “the agencies’ first concern was that access to data could not interfere with their operations. After all, we didn’t want to shut down citizen services!”
But real-time computing is challenging the status quo by enabling analytical processes to be applied to transactional databases without impacting the performance of operational systems. Ms. Goli describes the potential of this capability to transform government service delivery: “machine learning provided the ability to crunch large amounts of data and achieve real-time insight on that data. Visualization through the journey map and risk ratings brought these insights to the forefront, allowing front-line staff to easily consume them and embed them in their day-to-day business processes.”
IDC predicts that by 2019, 15% of government transactions (such as tax collection, welfare disbursement, and immigration control) will have embedded analytics. But there is still cultural resistance to new ways of working with machines. This is largely due to the perception, born out of the Industrial Revolution, that machines will replace peoples’ jobs. However, the McKinsey Global Institute argues that while 36% of healthcare and social assistance jobs will be subject to some degree of automation, less than five percent can be fully automated. In most cases, automation will take over specific tasks, rather than replacing entire jobs, with about 60% of all occupations having at least 30% of constituent activities that could be automated.
Ms. Goli explains that in OSR’s experience, automation has the potential to enhance the working experience: “with the introduction of advances in technology, such as machine learning, people are naturally scared that the machines will ultimately replace their jobs. However, what our prototype showed our staff was that this technology enriches, rather than replaces their jobs. Specifically, our staff can see how machine learning will take a lot of the frustration out of their jobs by enabling them to deal with customers holistically and help them to improve the customer experience.”
Data volume may have grown in recent years, but most companies are only really using 20%–50% of it to derive insights and make decisions
To be truly insight-driven, organizations should pull all of those captured numbers and isolated facts together into a single source that can generate a full picture of how every imaginable internal and external factor is impacting the business. Then, and only then, can companies make decisions in the moment and take action immediately.
How can your midsize business make the shift from data-driven to insight driven quickly with as little disruption as possible? Adjust the way everyone in your company – from the board room to the shop floor – uses data.
In the report, Forrester Consulting suggests that midsize business should consider embracing four fundamental capabilities:
1. Manage data with greater agility and flexibility
By adopting data management technology that goes beyond traditional, highly structured methods, you can consolidate data from every source into a single platform that can be accessed and acted on quickly – anytime, anywhere, and on any device. For everyone in your business, this can be a freeing experience when making on-the-fly decisions that contribute to the customer experience and bottom line.
2. Adopt analytics tools that are agile, flexible, and self-service
Thanks to the latest innovations in predictive and prescriptive analytics, midsize businesses can turn every functional leader and employee into a citizen data scientist. And all of this can be done without the intervention of IT or third-party analytics consultants. Self-service analytics are now intuitive enough to manipulate data and dig deep into the finer details of the problem at hand – even if you are using a mobile device at a customer location.
3. Get well-rounded insights by tapping into all areas of the business
Data volume may have grown in recent years, but most companies are only really using 20%–50% of it to derive insights and make decisions. Your business must combine currently leveraged data with the remaining 50%–80%.
4. Deliver insights that are contextual, actionable, and pervasive
Considering the pace of today’s world, analyzing data without the assistance of smart tools is too time-consuming. By the time a decision is reached, it’s too late. The data is outdated, the risk is impacting the business, and the opportunity is gone. Pulling analytics that are contextual and learning from past actions can generate more precise insights faster.
“Metadata management and ensuring data privacy for regulations such as GDPR joins earlier trends like AI and IoT, but the unexpected trend of 2018 will be the convergence of data management technologies,” said Emily Washington, senior vice president of product management at Infogix. “Big data has been the next big technology phenomenon for a long time, but businesses are increasingly evaluating ways to streamline their overall technology stack if they want to successfully leverage big data and analytics to create a better customer experience, achieve business objectives, gain a competitive advantage and ultimately, become market leaders.” The top data trends for 2018 were assembled by business leaders at Infogix who have decades of experience in information technology. The major trends include:
2018: The Year of Converging Data Management Technologies
Use cases have proven that leveraging data requires a multitude of separate tools for tasks like data quality, analytics, governance, data integration, metadata management and more.
To extract meaningful insights and increase operational efficacy, businesses will increasingly demand flexible, integrated tools to enable users to quickly ingest, prepare, analyze, act on, and govern data—while easily communicating insights derived.
Increased Importance of Data Governance
The deluge of data is growing, government regulations are increasing and teams have much greater access to data within an organization. Add to this the increasing need to leverage advanced analytics, and data governance has become more critical than ever.
Data governance capabilities have evolved in a way that provides complete transparency into a business’s data landscape—allowing them to combat increasingly complex regulatory and compliance demands and the shifting tides of business policies and business alignment.
The Continued Rise of the Chief Data Officer (CDO)
In today’s data-intensive environment, a CDO is more important than ever to navigate regulatory demands, successfully leverage data and manage enterprise-wide governance.
A CDO helps businesses manage unstructured and unpredictable data, while successfully leveraging advanced analytics and maximizing the value of data assets across the business enterprise.
Ensuring Data Privacy for Regulations such as the General Data Protection Regulation (GDPR)
When GDPR goes into effect in May 2018, it will strengthen and unify data protection rules for all organizations processing personal data for European Union (EU) residents.
Through analytics-enabled data governance, a business can not only locate personal data enterprise-wide, but monitor compliance, usage, approvals, and accountability across the organization.
The Proliferation of Metadata Management
Metadata is a growing trend for 2018. This “data about data” contains the information necessary to understand and effectively use data such as business definitions, valid values, lineage, and more.
Using such ontologies, organizations can understand the relationship between data sets, as well as enhance discoverability in metadata. Metadata management is critical in enterprise data environments to support data governance, regulatory compliance and data management demands.
The Monetization of Data Assets
Organizations recognize that data is either a liability or an asset. Metadata can be used to enable a deeper understanding of the most valuable information.
We are seeing more organizations using a combination of logical, physical, and conceptual metadata to classify data sets based on their importance, and businesses can apply a numerical value to each data classification, effectively monetizing it.
The Future of Prediction: Predictive Analytics to Improve Data Quality
With the continued concerns with data quality, and the volumes of data increasing, businesses are enhancing data quality anomaly detection with the use of machine-learning algorithms.
By using historical patterns to predict future data quality outcomes, businesses can dynamically detect anomalies in data that might otherwise have gone unnoticed or only found much later through manual intervention.
IoT Becoming More Real
Each passing year marks an increase in the number of connected devices generating data and there is a steep rise in focusing on extraction of insights from this data.
We are starting to see more and more defined IoT use cases leveraging data—from newer connected devices like sensors, and drones for analytics initiatives. With this, there is a growing demand for streaming data ingestion and analysis.
“As more data is generated through technologies like IoT, it becomes increasingly difficult to manage and leverage. Integrated self-service tools deliver an all-inclusive view of a business’s data landscape to draw meaningful, timely conclusions,” said Washington. “Full transparency into a business’s data assets will be crucial for successful analytics initiatives, addressing data governance and privacy needs, monetizing data assets and more as we move into 2018.”
CAMBRIDGE, Mass.–High-tech logistics systems have quickened the delivery of goods from manufacturing hubs to big-city markets in recent years. But speeding up the so-called last mile, from a local distribution center to a retailer or a customer’s home, has remained a challenge, especially in crowded urban centers. That’s a crucial hurdle, since the last mile of delivery routes tends to be the slowest and least cost-effective, according to Matthias Winkenbach, director of the Massachusetts Institute of Technology’s Megacity Logistics Lab, an initiative of the MIT Center for Transportation & Logistics.
It’s also where big-data analytics and the Internet of Things can be a powerful resource, Dr. Winkenbach told chief information officers, supply chain managers and other attendees at an MIT supply chain management R&D conference on Wednesday. “More and more companies are sitting on tons of data, but they don’t know what to do with it, or how to understand it,” he told CIO Journal. The MIT Megacity Logistics Lab team is trying to rectify that. It has worked with Anheuser-Busch InBev NV, the global brewery, and B2W, an e-commerce firm based in Sao Paolo, Brazil. The team’s former director, Edgar Blanco, was recently hired by Wal-Mart Stores Inc.WMT +1.16% as senior director of strategy and innovation, in order to apply the lab’s last-mile data analytics.
Until recently, Dr. Winkenbach said, gauging the efficiency of shipping routes has been limited to knowing when a package left a given depot, how far it travelled and the amount of time or fuel consumed in getting it there. But thanks to the consumerization of IT tools through smartphones, GPS-enabled devices, and IoT sensors and scanners — as well as the emergence of a fast, mobile Internet to collect and transmit large amounts of data from anywhere — shippers can now have a near-complete view of a given delivery route at any point in time, he said. That’s driving a hot new market for data-driven software firms that can help companies offer same-day deliveries. United Parcel Service Inc.UPS +0.61% in February led a $28 million funding round for Deliv Inc., one of a growing crop of last-mile delivery startups vying for accounts with retailers, restaurants and grocery stores. Deliv says it has roughly 4,000 retailers using its service including Kohl’s Corp. and Macy’s Inc.
Dr. Winkenbach said data-collecting tools can be used to better track the progress of delivery vehicles and inform route planning, by identifying patterns in delivery times.But they can also provide “transactional data” in the form of a clearer picture of what happens between a delivery truck and a customer’s doorstep, he said.
Many shippers want to know why some drop offs take much longer than others, an area Mr. Winkenbach calls the “black box” of delivery data, since for years so little off-vehicle data was available. He said geospatial data shows longer doorstep stops often occur in the most densely populated parts of a city, where many people live in high-rise apartments, he said. That means delivery workers are struggling to park, walking more or farther after parking, and climbing stairs when they get there.
Beyond that, so-called “crew traces” from smartphones, GPS and other geo-locating sources connected to delivery workers, can reveal key customer behavior — customers who chronically aren’t home, for instance — that is rarely factored into route planning, he said. Together, all this data can be fed into creating better delivery training programs, more efficient routes, and helping companies determine the best type of delivery vehicles. Sometimes multiple short-route deliveries on smaller vehicles, including bicycles, makes more sense than bulk deliveries in large trucks, for instance.
In most cases, Dr. Winkenbach said, his data shows that deliveries in big cities are almost always improved by creating multi-tiered systems with smaller distribution centers spread out in several neighborhoods, or simply pre-designated parking spots in garages or lots where smaller vehicles can take packages the rest of the way. One variable he has yet to crack is weather. “It’s a challenge to get accurate data on weather,” he said. “And all it takes is a big rainstorm and deliveries slow way down.
Microsoft’s new Azure SQL Data Warehouse
As reported by the website Top Tech News: Most As reported by the websitebusinesses are only able to crunch and analyze a small percentage of the massive amounts of data they have available, but several new offerings from Microsoft are aimed at changing that. Announced Wednesday during the Microsoft’s Build 2015 developers conference in San Francisco, the new tools and services offer cloud-based storage and computing power for organizations chasing big data intelligence.
Microsoft’s new Azure SQL Data Warehouse will let businesses add “unlimited compute power” to questions such as, “how will discounts affect inventories and margins?” A new service on top of the company’s existing Azure cloud platform, SQL Data Warehouse turns relational data warehousing into a pay-as-you-go, as-a-service offering. It is expected to roll out as a public preview in June. Also unveiled yesterday was Azure Data Lake, a “nearly infinite” data repository service that allows organizations to store, process and analyze exabytes of both structured and unstructured data. Would-be users are being invited to sign up to be notified when the service becomes available as a public preview. “Most businesses make decisions on a fraction of the data available to them, and this often leads to incorrect conclusions that can cost companies billions,” Scott Guthrie (pictured), Executive Vice President of Microsoft’s Cloud and Enterprise Group, said in a blog post on Wednesday. “But we believe that businesses should be able to derive insights from all of their data, no matter where it is stored, what format it is in and [no] matter how big that data is.”
The new Azure SQL Data Warehouse “offers developers the industry’s first enterprise -grade data warehouse that supports petabytes of data and scales compute separately from storage,” Guthrie said. He added the service will offer customers a 75 percent savings over cloud data warehouse offerings. Guthrie also pointed to a number of other additions Microsoft is making to its Azure cloud platform. Previewed during the Build conference, a new elastic database pool technology will let users of Azure SQL Database “easily manage hundreds to thousands of separate databases per client as a single scalable service,” Guthrie noted. Microsoft also introduced Visual Studio Code, a new Office Graph API; demonstrated Docker support for Linux and Windows Server; and previewed releases of .NET Core runtimes for Linux, Windows and Mac OSX.
Big data: the future of logistics
As reported by the website Luxembourg DELANO: “I am convinced there are opportunities for developing the logistics sector by using ICT,” Étienne Schneider, Luxembourg’s deputy prime minister. But “data alone does not generate opportunity. We need to turn them into smart data.” He was speaking at the “Big data: the future of logistics” conference, organised by KPMG, the Luxembourg-Poland Business Club and Poland’s embassy to the Grand Duchy. “Big data refers to the idea that society can do things with a large body of data that weren’t possible when working with smaller amounts,” according to The Economist. Originally it was applied to fields such astrophysics and automated translation. “Now it refers to the application of data-analysis and statistics in new areas, from retailing to human resources,” the publication explained. Noting that logistics is a big part of the Luxembourg government’s economic growth programme, Schneider said in his speech that big data had the potential to solve problems from supply chain management to road congestion. And with rising concerns over privacy and hacking, Luxembourg offers high security standards for handling sensitive data, while still allowing high efficiency, driven by its experience in the financial sector, argued Schneider.
He spoke in favour of further linking the multimodal transit centres in Luxembourg and Poland, meaning Luxembourg exports could more efficiently access eastern Europe via Poland and Luxembourg could serve as a hub for Polish goods headed towards countries such as France and Spain. Schneider, who is also the economy and defence minister, said that during a recent mission to Poland he was impressed by the level of the IT skills of recent university graduates. One advantage of big data for a smaller economy is that a country does not have to be big to take advantage of it, said Bartosz Jałowiecki, Poland’s ambassador to the Grand Duchy. Both countries are well positioned to profit from big data’s benefits since both have flexible economies and outlooks, in the ambassador’s view. Pascal Denis of KPMG cited studies showing the amount of data is doubling every year. But what to do with the mounds of information? Piotr Reichert of Comarch, a Polish firm which provides IT services to large organisations, said its Luxembourg unit has used big data findings to develop an entirely new supply chain finance product, for instance. Payment delays “for small suppliers” are “sometimes a killer”. So the system matches sellers who have buyers with banks and has been used to settle more than 300m invoices in 12 countries since 2008, he said. Rafał Markiewicz of InPost, founded as a private competitor to state-run Polish Post, said his firm provides automated parcel distribution machines (and is currently testing automated laundromat drop off and pick up machines) in 21 countries from the Baltics to Chile. InPost based its finance unit in Luxembourg since electronic payments are an important part of e-commerce in many markets. More than 90% of e-commerce customers pay online in the UK, compared with roughly 10% in Russia, according to Markiewicz.
His colleague Maciej Jaroszuk-Rozycki said big data helps the company learn how to better manage delivery to its outlets, “because there is a limited amount of locker spaces”. One location in a trendy part of Warsaw needs to be restocked six times a day, he said. In the UK around half of parcels are picked up after 4pm and roughly one third are collected over the weekend, for example. Michael Kreutzmeyer explained that his firm, Luxembourg-based Dematic, provides hardware and software for automating warehouses, including 50 Amazon distribution centres. Big data helps plan staffing for seasonal peaks in workload such as the winter holiday season. In addition, he observed a new trend that consumers will now order, say, ten pair of shoes of different colours and sizes, and then return the nine they do not like. Big data helps a company like Amazon restock its warehouses so those items can be resold quickly. That is important because, citing an old retailing maxim, “What you can’t sell today, you can’t sell tomorrow”. Francis Castelin of Transalliance, a transport firm that moved its headquarters from the French city of Nancy to Luxembourg in 2010, said technology has the potential to fundamentally shift how the sector is viewed by customers. “Big data could help logistics become an investment and not a cost”.
Unlocking Big data
4 lessons for every entrepreneur creating Big Data Solutions
(BILL SCHMARZO, CONTRIBUTOR,Chief Technology Officer, EMC Global Services)
I recently taught an MBA course at the University of San Francisco titled the “Big Data MBA.” In working with the students to apply Big Data concepts and techniques to their use cases, I came away with a few observations that could be applied by any entrepreneur.
1. Understand the customer’s problem. To ensure that your solution adds value, start by conducting extensive primary and secondary research on both the problem and the value of the solution. To understand your targeted customers, develop personas early in the process that serve as the “face of the customer.” Document the types of questions they ask and decisions they make. Then use the resulting insight to identify and prioritize data sources that you could be capturing about your customers, products and operations based upon business value and ease of implementation.
2. Understand how your product fits in the customer’s environment. Companies have big investments in their data and technology environments. They will not be easily persuaded to toss out that investment. Instead, figure out how your solution can leverage or extend your targeted customers’ existing data and technology investments. Data, analytics, reports, dashboards tools and even SQL are strategic organizational assets. Explore ways to extend or free up those assets with new big data technologies, products and capabilities. By adding $1 now, they can free up or add $10 of value to their existing investments, such as Business Intelligence and data warehousing. That’s always a winning strategy!
3. Build upon open source and cloud technologies. There is a compelling suite of open source technologies, many supported by the Apache Foundation, that are free, scalable and that allow organizations to quickly develop and get products to market. These technologies include:
Hadoop, a programming framework that supports the processing of large data sets in a distributed computing environment.
Spark, an in-memory open-source cluster-computing framework that provides performance up to 100 times faster for in-memory analysis and applications.
YARN, which enables multiple data processing engines on top of Hadoop such as interactive SQL, real-time streaming, and advanced analytics, along with the traditional MapReduce batch processing.
Mahout, a suite of scalable machine learning algorithms focused primarily of collaborative filtering, clustering and classification.
HBase, a column-oriented database management system that runs on top of HDFS; very useful for sparse data sets, which are common in many big data use cases.
Hive, an open-source data warehouse system for querying and analyzing large datasets stored in Hadoop files.
R, a free software programming language and software environment for statistical computing and graphics.
The entrepreneur should stand on the shoulders of those who have already built solutions to create your unique and compelling differentiation. Leverage open sources products and the cloud for your development environment. Light your hair on fire to get initial prototypes out to market as quickly as possible. Heavily instrument your product so that you have details about how customers are trying to use your product. Learn and evolve quickly. Speed is everything, with customer service a close second.
4. Provide a compelling, short payback ROI. Help organizations find new ways to monetize their data and analytic assets. Focus on the business stakeholders by providing products and solutions that help them optimize their key business processes. To accomplish this, develop an initial ROI for your product and use it as compelling evidence for your customers to test, try and buy your product. Empowering front-line employees to deliver new services to customers is a great way to monetize your data and analytic assets and drive that ROI. If you don’t know how you product makes your targeted customers money, then don’t expect them to figure it out on their own. It’s very encouraging to see MBA students empowered to be bold and brave in creating new business opportunities. And as I told my MBA class, the days of the MBA and business leaders delegating data and analytic decisions to IT are over. Business leaders (and MBA students) need to start owning these new sources of monetization, and the time is now.
Techcrunch: How Big Data Will Transform Our Economy
(Reading TechCrunch) The great Danish physicist Niels Bohr once observed that “prediction is very difficult, especially if it’s about the future.” Particularly in the ever-changing world of technology, today’s bold prediction is liable to prove tomorrow’s historical artifact. But thinking ahead about wide-ranging technology and market trends is a useful exercise for those of us engaged in the business of partnering with entrepreneurs and executives that are building the next great company. Moreover, let’s face it: gazing into the crystal ball is a time-honored, end-of-year parlor game. And it’s fun. So in the spirit of the season, I have identified five big data themes to watch in 2015. As a marketing term or industry description, big data is so omnipresent these days that it doesn’t mean much. But it is pretty clear that we are at a tipping point. The global scale of the Internet, the ubiquity of mobile devices, the ever-declining costs of cloud computing and storage, and an increasingly networked physical word create an explosion of data unlike anything we’ve seen before. The creation of all of this data isn’t as interesting as the possible uses of it. I think 2015 may well be the year we start to see the true potential (and real risks) of how big data can transform our economy and our lives.
Data-driven decision tools are not only the domain of businesses but are now helping Americans make better decisions about the school, doctor or employer that is best for them. Similarly, companies are using data-driven software to find and hire the best employees or choose which customers to focus on.
But what happens when algorithms encroach on people’s privacy, their lifestyle choices and their health, and get used to make decisions based on their race, gender or age — even inadvertently? Our schools, companies and public institutions all have rules about privacy, fairness and anti-discrimination, with government enforcement as the backstop. Will privacy and consumer protection keep up with the fast-moving world of big data’s reach, especially as people become more aware of the potential encroachment on their privacy and civil liberties?.
With over $1.2 trillion spent annually on public K-12 and higher education, and with student performance failing to meet the expectations of policy makers, educators and employers are still debating how to fix American education. Some reformers hope to apply market-based models, with an emphasis on testing, accountability and performance; others hope to elevate the teaching profession and trigger a renewed investment in schools and resources. Both sides recognize that digital learning, inside and outside the classroom, is an unavoidable trend. From Massive Open Online Courses (MOOCs) to adaptive learning technologies that personalize the delivery of instructional material to the individual student, educational technology thrives on data. From names that you grew up with (McGraw Hill, Houghton Mifflin, Pearson) to some you didn’t (Cengage, Amplify), companies are making bold investments in digital products that do more than just push content online; they’re touting products that fundamentally change how and when students learn and how instructors evaluate individual student progress and aid their development. Expect more from this sector in 2015. Now that we’ve moved past mere adoption to implementation and utilization, 2015 will undoubtedly be big data’s break-out year.
The big data and cloud join forces
According to the website report www.tendencias21.net two ICT initiatives are monopolizing the headlines about technology in recent times, with the promise to revolutionize computing, business practice, education and most areas of knowledge in which one can think.
On the one hand, explains in his web Institute IMDEA Networks, a research institute of the Community of Madrid, mass data or large-scale data (Big Data) are an emerging paradigm for managing large amounts of information beyond the capabilities technology that supports traditional databases. On the other hand, cloud computing (Cloud Computing) emerges as a paradigm in distributed computing systems, whose goal is to offer the software as a service over the Internet. Cloud computing offers a flexible delivery model and highly scalable to withstand the demands of storage and computing technologies big data infrastructure. Both technologies converge to offer a huge range of data to explore and to obtain meaningful analysis as well as a growing range of services and resources with applications in any field that is affected by the innovation and development of ICT.
Both cloud computing and Big Data mature rapidly and its use is spreading, but it takes, explains Imdea, a determined effort to create a holistic environment in which both can thrive and achieve their full potential. The scientific objective of Cloud4BigData ambitious project – launched recently by Imdea, the Polytechnic University of Madrid and Universidad Rey Juan Carlos – is to facilitate the convergence of Big Data technologies to their underlying cloud infrastructure to achieve high levels of efficiency, flexibility , scalability, high availability, quality of service, ease of use, security and privacy.
Cloud4BigData unambiguously address the current shortcomings and deficiencies of Big Data and Cloud Computing, also taking advantage of their strengths. From the safe management to the efficient processing of the data, the project aims to combine and integrate differentiated and specialized technologies into one unified platform. The project will also demonstrate their competence in areas of emerging application with very demanding requirements that demand cloud and Big Data technologies such as machine to machine (machine-to-machine) technology, the Internet of Things (IoT – Internet of Things) , smart or intelligent technologies (such as smart Grid, smart grid, smart Cities, smart cities, intelligent transportation, smart transport, etc.) as well as traditional application areas, such as banking, telephony, multimedia communication, distributed simulations, etc., which require functionality beyond the current capabilities of Big Data technologies.
Cloud4BigData is funded by the Community of Madrid, through the Programme for R & D between research groups Technologies 2013, co-financed by the Structural Funds of the European Union. It began in October 2014 and will end in September 2018. Another project of big data, SciServer, supported by the National Science Foundation (NSF) US, aims to build a flexible and long-term ecosystem to provide scientists access huge data sets of observations and simulations.
Alex Szalay, Johns Hopkins University, is the principal investigator of the project, five years specified duration, and the architect of the Scientific Archive Sloan Digital Sky Survey (SDSS), a project to map the entire universe. The latter is where did the SciServer idea explains Szalay. “When the SDSS began in 1998, astronomers had data of less than 200,000 galaxies,” says Ani Thakar, an astronomer at Johns Hopkins, which is part of SciServer team. “Five years after starting SDSS, we had about 200 billion galaxies in our database. Today, SDSS data exceeds 70 terabytes, covering more than 220 million galaxies and 260 million stars.” The Johns Hopkins team created several online tools to access data from SDSS. For example, in the SkyServer site, anyone can navigate through the sky, details about the stars or find objects using multiple criteria. The site also includes educational activities in class lists to allow students to learn science from art data. For more advanced analysis, created Casjobs, where you can run queries of up to eight hours and store the results in a personal database. With each new tool, the user community grew, which led to make new scientific discoveries.
Big data is going to get a big boost from the European Union, which will match an industry consortium’s €2 billion investment with €500 million of public money over the next five years. Companies including Atos, IBM, Nokia Solutions and Networks, Orange, SAP, and Siemens, along with several research bodies, will invest in the public-private partnership (PPP) from January 2015. The partnership will invest in research and innovation in big data fields such as energy, manufacturing and health to deliver services including personalized medicine, food logistics and predictive analytics. Other products could include forecasting crop yields or speeding the diagnosis of brain injuries. This investment will give a boost to the struggling European big data industry, European Commission vice president Neelie Kroes said during a news conference in Brussels. “Europe is trailing behind. Virtually every big data company is from the USA, none are from Europe,” she said. “That has to change and that is why we are putting public money on the table.” The money is needed to help companies process some of the 1.7 million gigabytes of data she said is generated around the world each minute. This data, including climate information, satellite imagery, digital pictures and videos, transaction records and GPS signals should be put to use by European companies, Kroes said. The 25 companies forming the Big Data Value Association also see an immediate need to get their act together and start competing, said association president Jan Sundelin, who is also CEO of the Dutch e-commerce company Tie Kinetix. Europe is one of the largest retail markets in the world, yet non-European companies “know more about our consumers and what we are doing in Europe than we know ourselves,” he said during the news conference, where he invited other companies and startups to take part in the research. The investments in the industry will also support “Innovation Spaces” that will offer secure environments for experimenting with both private and open data, the Commission said. Plans to experiment with private data highlight one of the challenges of working with big data. While today’s datasets are so huge and complex to process that they require new ideas, tools and infrastructures they also require the right legal framework, systems and technical solutions to ensure privacy and security, the Commission said. It will make data protection and pseudonymization mechanisms technical priorities for the project. Further research into technical solutions to integrate privacy- and security- enhancing features will also be funded by the Commission. Moreover, the Commission will work with member states and others to make sure that businesses receive guidance on how to make data anonymous and use pseudonyms to perform personal data risk analyses, while also providing guidance on tools and initiatives available to enhance consumer awareness. The partnership that was signed in Brussels on Monday is the sixth huge EU technology investment program that it hopes will catapult it into global leadership. In July for instance the Commission partnered with the private sector to invest €5 billion in Europe’s electronics sector.





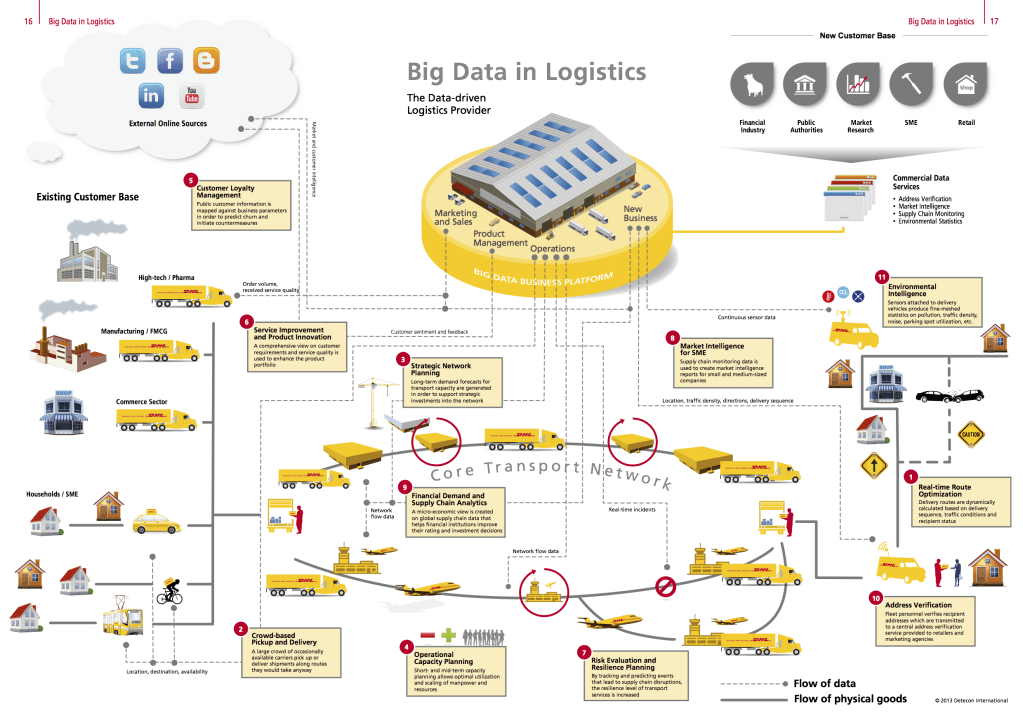

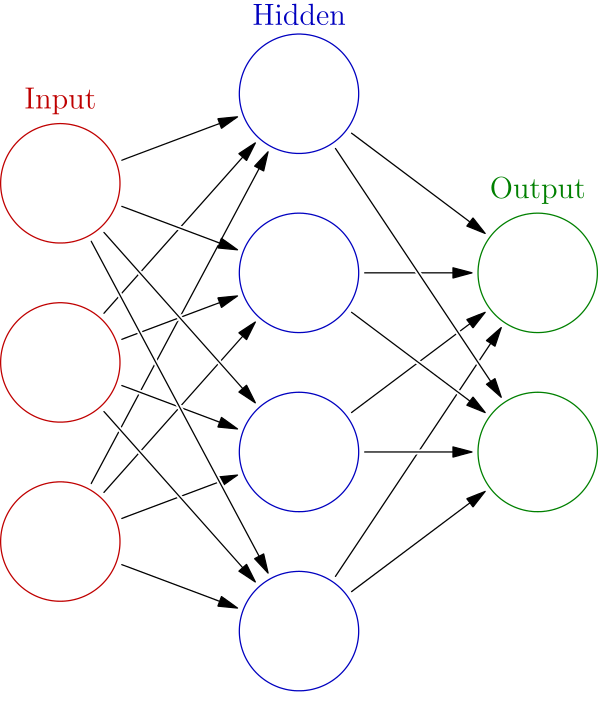
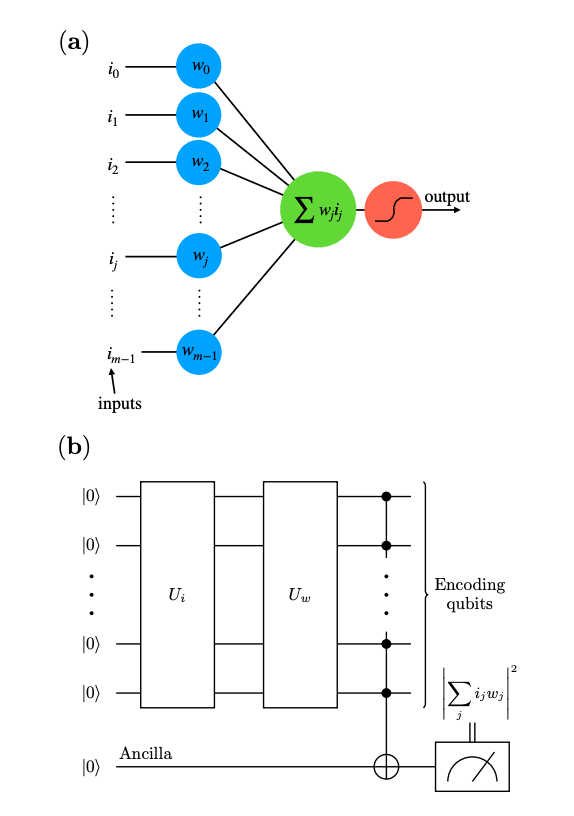








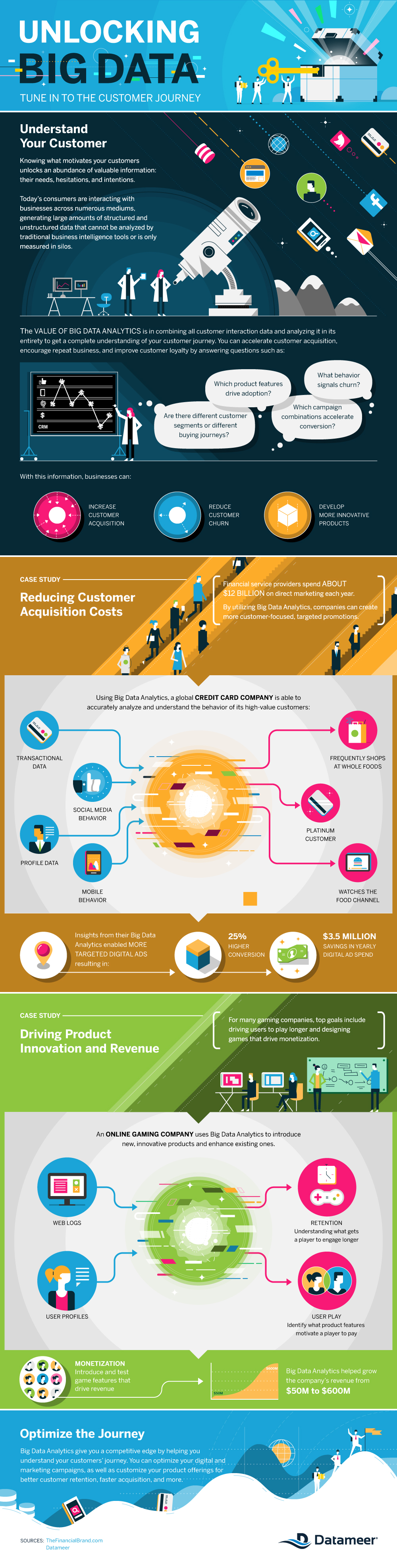

{kind=link}
[…] BIG DATA […]
LikeLike